I’ve built four larger software prototypes with AI agents in the last year. Only one made it to production. The others are AI slop. How do we get over that quality hump to feel good about our AI developed software?
So I went looking. I read the skill libraries like GStack and SpecKit. I talked to AI-forward friends about how to make agents run longer and verify their own work. OpenClaw came out and demonstrated what serious investment in verification looks like.
The more I built, the more I noticed something else: I need to put more constraints on my agents. Claude Code, Codex, and Cursor are great generalists. They’ll attempt almost any task and one-shot simple ones! But overall the quality of what comes back is variable. Especially as systems grow. Doesn’t matter how carefully you construct the prompts.
What follows are five moments that taught me what the missing pieces are. Each one started as a frustration. Each one turned into a first principle. Together they pointed at something specific enough that I stopped working on all the other prototypes and put everything into one thing.
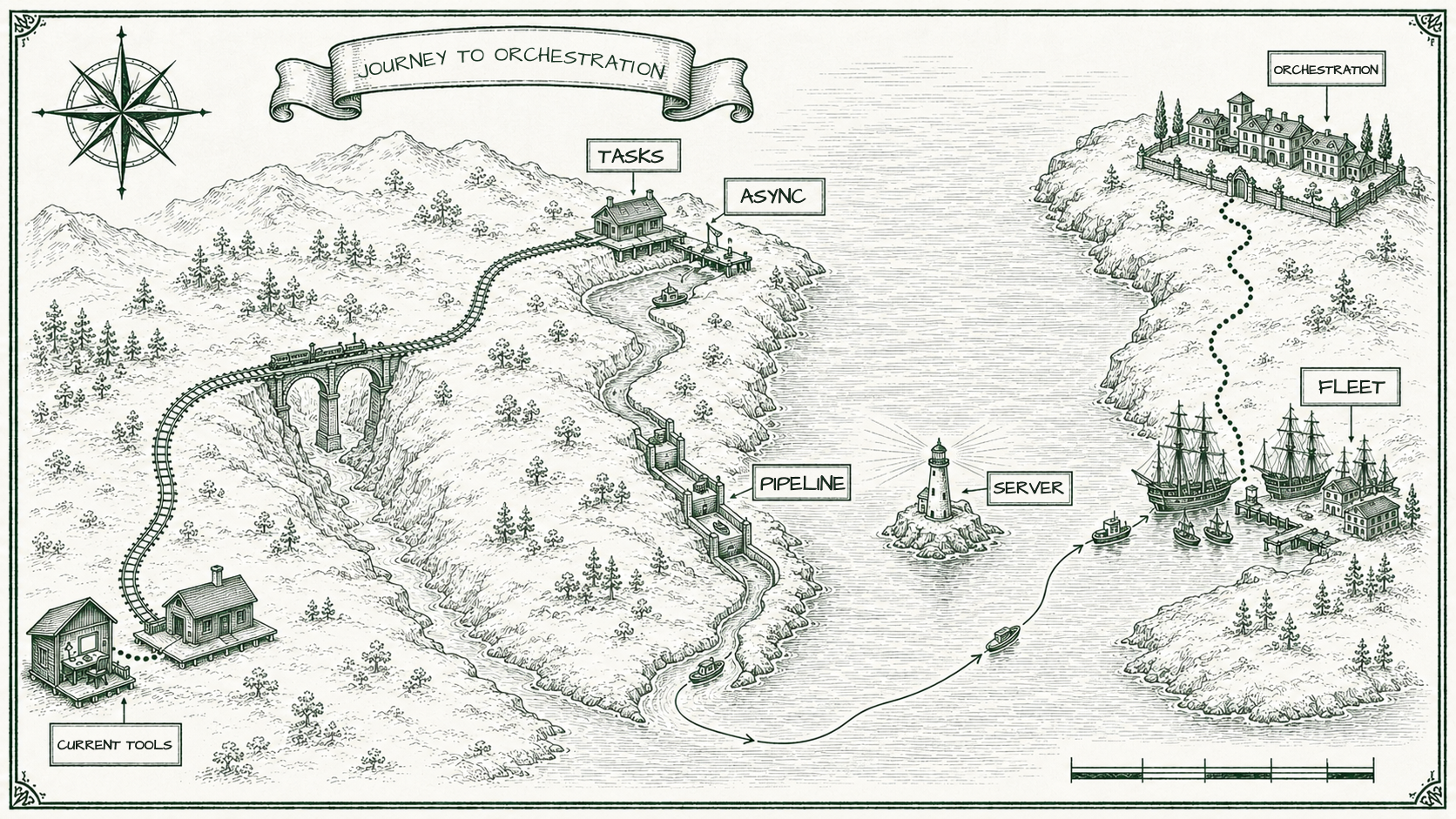
1. Tasks not chats
I wrote what should have been one feature as a long chat with Claude Code. Forty-five minutes in, I noticed the model had forgotten a constraint we’d agreed on twenty exchanges earlier. The context had drifted, and so had the work. I’d pushed code that didn’t match what we started building.
Two things were going wrong at once. I was writing feature requests that were too large for one chat to hold. And I wasn’t clearing context between tasks, so old decisions were polluting new ones. The combination meant the model was operating on a context window that was too crowded and too stale. Long chats accumulate context the way a bad meeting accumulates topics. By the end, nobody remembers what decisions were made in the first half. What I needed was Claude working off a ticket.
Tasks (or tickets) force a clean start. When the task is done, you close it and the next task starts fresh. That’s how engineers work in agile: small, scoped, written down. It’s also how the rest of the tooling already works. Jira and Linear are built for this. Tickets, scoped, built, closed, next. Agents fit perfectly into that flow - we don’t need chats, we need scoped tasks.
The other thing tasks unlock is parallelism. I tried the parallel version first in chats — five terminal windows, five Claude sessions, switching between them. Lost my place inside ten minutes. With proper tasks, you spin up ten agents working independently and come back to the outcomes. Tasks aren’t a UI choice. They’re how you scale beyond one of you.
2. Servers not terminals
I was in the garden all day, but I had a big refactor going through review on my laptop. Over fifty rounds of cloud-bot feedback, fixes, test runs, more feedback. I had set the agent up with a /loop command to handle the cycle: read review, fix, test, push, wait for next review, repeat. Then I went outside.
Except I brought the laptop with me. I had to check it every ten minutes to make sure the agent didn’t get stuck on a permission prompt, a failed test, or a question it couldn’t answer. The agent was running. And I was still tethered to it, just from twenty metres away.
Another time I had several agents working on things, closed the laptop and stepped away for an hour. Came back to dead sessions and lost progress.
Both failures point at the same thing. The promise of an agent is that it works while you’re not there. But “not there” turns out to mean “still at the keyboard” — or “still checking every ten minutes.” Close the laptop and the work stops. Stay close enough to monitor and you haven’t actually freed up your time. The agent isn’t independent of you — it’s tethered to your attention. That’s the meme of engineers carrying open MacBooks around the office, balanced on forearms. The tools are fighting the shape of how agents are supposed to work.
3. Async not synchronous
I want a hundred developers working on my ideas in parallel. Not one agent I have to babysit.
I have ideas faster than I can supervise execution. Most engineers do. The bottleneck isn’t generating work; it’s overseeing work. I can only run a few agents at a time because I can only watch so many at once.
Async inverts that. I queue work. The agents run. I come back to outcomes. The interaction shifts from “watch” to “review what’s done.” The supervision cost stops being proportional to the number of agents running.
This is the difference between delegating and pair programming. Pair programming is great. It’s also what every current tool optimises for, because pair programming is what one engineer does with one assistant. Delegating is what a manager does with a team. The shape is fundamentally different. The tools haven’t caught up yet.
4. Fleet not single agent
Five terminal windows. Five Claude sessions. Five worktrees. Different tasks, different repos, different branches.
By window three I’d lost track of which one was working on what. Window four had a question waiting that I never saw because I was answering window two. And then worse: I told agents to commit and push, and they did – to the wrong branches. The agent did what I said. I was the one who couldn’t keep five contexts straight in my head. I’ve committed the wrong work to the wrong branch more than once.
Stacking windows isn’t fleet operation. It’s pretending to be the orchestrator of a system that doesn’t have orchestration built in. The cognitive overhead of tracking five worktrees, five tabs, five branches eats the productivity gain of parallelism. And it produces actual mistakes I have to spend hours cleaning up afterwards.
The orchestration needs to be part of the product. One place to see all running agents; what state each is in, which branch, which need attention. Then the cognitive load goes down. That’s the only way fleet-scale work is possible.
5. Pipeline not freeform
The agent kept skipping steps.
I’d ask it to write tests first. It would write the implementation first and bolt tests on after — or skip them entirely. I’d tell it to verify the output. It would declare the work done without checking anything. I’d put “review your changes against the spec before you finish” in the prompt. It would acknowledge the instruction and then not do it.
I’ve seen this first hand more times than I want to admit. The advice you’ll get is “write better prompts” or “use a system prompt for the rules.” Neither worked reliably for me. The model was optimising for what looked like a good answer in the context window — not for the instruction buried twenty messages ago, not for the system prompt competing with the user’s actual request, not for the rule that contradicted the path it had just committed to. When the structure is words, the words get weighted against everything else.
The fix isn’t a longer prompt. It isn’t louder instructions. It isn’t please for real this time write the tests. The fix is to take the steps out of the prompt and put them in the system. A pipeline runs the stages in the right order. It refuses to advance when a stage doesn’t pass. The agent doesn’t get to skip the verification step because the verification step isn’t a thing the agent decides about — it’s a gate the runtime enforces.
Spec, plan, review, test, ship. Each stage with a verification gate. The agent works inside the stage. The stage is what makes the structure load-bearing.
This is where this piece connects to the last one. The previous Field Note was about closing the loop — the loop has two halves, verification and heartbeat, and both have to be real. A pipeline is what a load-bearing loop looks like in practice. The heartbeat is the pipeline advancing. The verification is the gate at each stage. The flexibility lives at the spec layer, not the execution layer.
I was tired of agents skipping the work. I wanted the system to enforce it.
What this points at
Five moments. Five frustrations. Five principles. They look separate, but they’re angles on the same realisation.
Existing tools are converging on a specific shape — single-task, single-agent, single-screen, synchronous, freeform. Optimised for one engineer at a keyboard, exploring. That shape is genuinely good and getting better. If that’s the work you do, you’re well served.
The shape of the work I actually do is different. Across tasks. Across repos. With memory in the system, not in my head. With agents that keep going when I close the laptop. With outcomes I review, not sessions I watch. That’s the shape that produces quality. Not better prompts. Not bigger models. Better constraints, better structure, better surface for the operator.
That’s the second direction. Tasks instead of chats. Servers instead of terminals. Async instead of synchronous. Fleet instead of single agent. Pipeline instead of freeform. It’s not better than what Claude Code and Codex and Cursor are building. It’s a different answer to a different question. And almost nobody is building it.
That’s what Lotsa (previously Pilot) is. The first version will be open-source — small, focused, local. It’s also the version I’m using to build the next versions. Recursive credibility, or just dogfooding, depending on how generous you’re feeling.
If you've felt any of the five moments above, you're the audience for what I'm building. That's Lotsa.
Try Lotsa →The next Field Note is in two weeks. If you want it in your inbox, subscribe below.
This essay sits within a broader thesis on AI coding. See the full argument →